Probabilistically Reasoning About Code
Designing program analysis tools requires careful tradeoffs between accuracy and
scalability. We have been trying to extend the analyzer from making discrete judgments
(“The program might dereference an invalid pointer at Line 57” vs.
“The dereference at Line 57 is definitely valid.”) to providing
numerical estimates of suspicion. The probabilistic model provides the ideal substrate for
incorporating user feedback, for figuring out whether changes to code are introducing bugs,
and for incorporating observations from test executions into the static analysis pass.
[PLDI 2018],
[PLDI 2019],
[FSE 2021],
[ICSE 2022]

Subspecifications: Local Explanations for Program Behaviors
Over the last fifty years, programming language and formal methods researchers have
developed a range of sophisticated verification and synthesis algorithms. There has been
much less work asking whether programmers can understand this code. Subspecs are our attempt
at answering this question. Roughly speaking, the idea is to use the global specification to
reverse-engineer constraints that locally describe parts of the implementation.
[OOPSLA 2023],
[VLHCC 2024],
[HotNets 2024]
Synthesizing Datalog Programs
Datalog is an extremely simple logic
programming language. In the simplest case, a Datalog program is simply a collection of
universally quantified if-then rules. For e.g., my ancestor's parent is also my ancestor.
Running a Datalog program amounts to repeatedly evaluating these rules until saturation.
Starting about thirty years ago, Datalog programs have seen wide adoption for developing
program analyzers. Question: Can we automatically synthesize Datalog programs from examples?
[IJCAI 2019],
[POPL 2020],
[PLDI 2021],
[UIST 2021],
[OOPSLA 2023]
Semantic Regular Expressions
SemREs extend classical regular expressions with the ability to query external oracles:
\[
r ::= \emptyset \mid \epsilon \mid a \mid
r_1 + r_2 \mid r_1 r_2 \mid r^* \mid
r \land \langle q \rangle
\]
There is just one new construct, \(r \land \langle q \rangle\), which allows the user to
talk about strings which match \(r\) and which are also “accepted” by the oracle
\(q\). The oracle can be any external program: LLMs, databases, or DNS lookups. SemREs allow
the user to search newspaper articles for the names of politicians, source code for string
literals that look like passwords, email addresses coming from non-existent domains, and so
on. The first question, of course, is whether we can build grep. The oracle is expensive to
invoke, so we have to be careful in how we use it. Once we start talking about SemREs,
numerous other questions naturally arise: Can we sample strings? What are the
language-theoretic consequences of the formalism? Etc.
[Preprint]
Code2Inv: Inferring Loop Invariants by Reinforcement Learning
Inferring loop invariants is an archetypal challenge in automatic program verification.
Existing systems may be largely described as carefully searching through a space of
potential invariants, and aggressively pruning infeasible branches. But programs can be
represented as graphs—abstract syntax trees, def-use graphs, etc.—and graph neural networks
have previously shown surprising success in various graph search and combinatorial
optimization problems. Code2Inv is a system that considers loop invariant synthesis as an
instance of reinforcement learning, where the learner plays against an adversarial theorem
prover and learns the structure of successful loop invariants. In preliminary experiments,
the system learns from significantly fewer calls to the theorem prover, and can tolerate
large numbers of confounding variables commonly seen in large software systems.
[NeurIPS 2018 Spotlight],
[Code]

SyGuS: Interchange Format for Syntax-Guided Synthesis Problems
To facilitate both the development of application-specific program synthesizers and
algorithmic research into new backend synthesis algorithms, we proposed the SyGuS
interchange format. We based its design on the observation that program synthesis problems
can often be decomposed into a semantic specification describing the input-output
behavior of the desired program, and a syntactic specification describing its
appearance.
[Proposal],
[Format specification],
[Repository of solvers and benchmarks]
Synthesize a function \(f(x, y)\) of the form \(\texttt{IntExpr}\), where
\[
\texttt{IntExpr} ::= 0 \mid 1 \mid x \mid y \mid
(+\ \texttt{IntExpr}\ \texttt{IntExpr}) \mid
(\texttt{ite}\ \texttt{BoolExpr}\ \texttt{IntExpr}\ \texttt{IntExpr}),
\]
\[
\texttt{BoolExpr} ::= (\leq\ \texttt{IntExpr}\ \texttt{IntExpr}) \mid
(\texttt{and}\ \texttt{BoolExpr}\ \texttt{BoolExpr}),
\]
and such that for all integers \(x\), \(y\), \(f(x, y) \geq x\) and \(f(x, y) \geq y\).
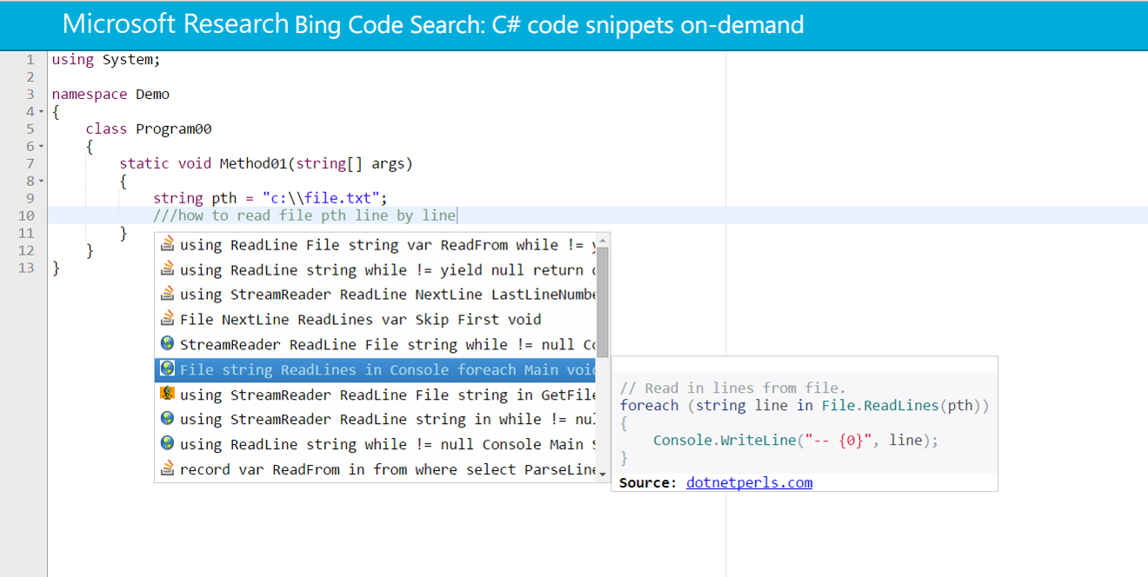
SWIM: Natural Language Code Search
SWIM synthesizes idiomatic snippets of C# code to answer API-related natural language
queries such as "Generate MD5 hash code". By not having to explicitly specify type or method
names relevant to their query, SWIM allows the programmer to explore the API framework. The
patterns of idioms supported are quite general, including constructs such as if statements,
and while and for loops.
[ICSE 2016]
StreamQRE and DReX: Domain-Specific Languages for Stream Processing
StreamQRE is a domain-specific language for efficient stream processing. Queries are
modular, have simple, clear semantics, and enable fast one-pass evaluation. It borrows ideas
both from quantitative automata and from relational
databases. DReX is a related formalism tailored to the domain of string transformation
utilities. These are the main software artifacts I developed during my Ph.D.
[StreamQRE],
[DReX],
[LICS 2014],
[POPL 2015],
[ESOP 2016],
[PLDI 2017],
[Thesis]
Last updated: Sat Aug 23 20:50:12 PDT 2025






